Next.jsでMarkdownをHTMLに変換して自動目次生成機能を実装する
はじめに
今回は Markdown で記述したブログ記事を HTML に変換しスタイルを当て、さらに目次を自動生成して表示する機能を実装します。
目指しているのは Zenn や Qiita ページ右側に表示される目次機能のイメージです。
目次をクリックすると該当見出しへページ移動する機能も実装します。

Markdown を HTML に変換する
Markdown を HTML に変換するライブラリは調べるといくつかありました。
- showdown.js
- markdown-js
- marked
- zenn-markdown-html
最初は marked で機能の実装を行っており、変換規則や スタイリングを自由に書き換え可能で、使い勝手は悪くない印象です。highlight.js と組み合わせるとコード表示のシンタックスハイライトも実現できました。
marked
highlight.js demo
一方、zenn-markdown-html という Zenn 公式の変換ライブラリは、ずば抜けて完成度が高く、CSS も用意されたものを当てるだけで Zenn の記事のような見た目が実現できました。もともと完成形は Zenn や Qiita をイメージしていたので、棚からぼたもちです
marked で実装してるときは このライブラリの存在知らず、もっと早く気付ければよかったなぁ。。。
zenn-editor
目次となる h タグ要素を抽出する
zenn-markdown-html で変換後の HTML から、目次となる h タグのテキストや id を抽出します。DOM 要素の取得といえば document.querySelectorAll メソッドなどが利用できるでしょう。
zenn-markdown-html の戻り値は string 型のため、前処理として DOMParser というクラスを利用して string 型の HTML を Document オブジェクトに変換します。
目次情報は Next.js の SSG(Static Site Generation)で生成可能なデータのため、getStaticProps 関数の中で次のようにコードを実装しました。
/**
* 静的ページ生成に必要なデータを生成し、コンポーネントにpropsとして渡す
*/
export const getStaticProps: GetStaticProps = async (context: any) => {
// ブログ記事markdownをHTML(string)に変換する
const blogData = await getBlogContentData(context.params.id);
// HTML(string)をHTML(DOM)に変換する
let domParser = new DOMParser(); // → エラー発生!
const blogContentHtml = domParser.parseFromString(
blogData.blogContentHtml,
"text/html"
);
// HTML(DOM)から hタグ要素を抽出して{hタグレベル、タイトル名、リンク先}、を取得する
// ここにコードを書く
// blogContentHtml.querySelectorAll ...
ところが次のようなエラーに遭遇しました。
DOMParser is not defined
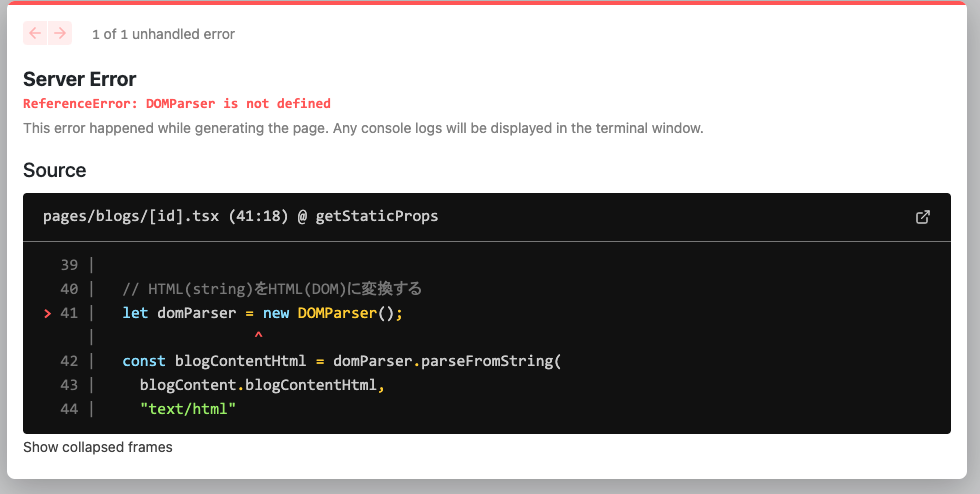
DOMParserは Javascript に標準で組みこまれているクラスのはずですが、何故 not defined になってしまうのでしょうか。
Next.js の落とし穴
エラーの原因は Next.js の仕組みにありました。
Next.js における jsx ファイルでは、次の関数をよく使用していると思います。
- 関数コンポーネント
- getStaticProps
- getStaticPaths
ここで注意したいのは、getStaticProps や getStaticPaths はブラウザ側ではなくサーバー側で実行されるということです。
よく調べてみると、DOMParser クラスはブラウザ側の Javascript には組み込まれていますが、サーバー側の node.js には存在しないクラスでした。
つまり、getStaticProps 内のコードはサーバ側の node.js で動作するため、DOMParser クラスが見つからずエラーになるということでした。
node.js で動作する DOMParser
このエラーに対する解決方法は2つ考えられます。
・関数コンポーネント内で DOMParser を利用して変換処理を実装する
・Node.js で動作する DOM パーサーライブラリを利用する。
前者は手っ取り早いですがブラウザ側の処理となりレスポンスを悪化させるため、Next.js の SSG のメリットが失われてしまいます。今回は後者で実装を進めます。
今回は jsdom というライブラリを利用します。
次のコマンドでライブラリ本体と型定義ファイルをインストールします。
npm install --save jsdom
npm install --save-dev @types/jsdom
基本的な使い方は次の通りです。一発で HTML(String)を DOM に変換できますね。
import { JSDOM } from "jsdom";
const dom = new jsdom.JSDOM(`<!DOCTYPE html><p>Hello world</p>`);
dom.window.document.querySelector("p").textContent; // 'Hello world
これでサーバー側(Node.js)の領域である getStaticProps 関数内で、document.querySelectorAll メソッドが利用できるようになりました。
再トライ
zenn-markdown-html が出力する HTML の構造を解析します。
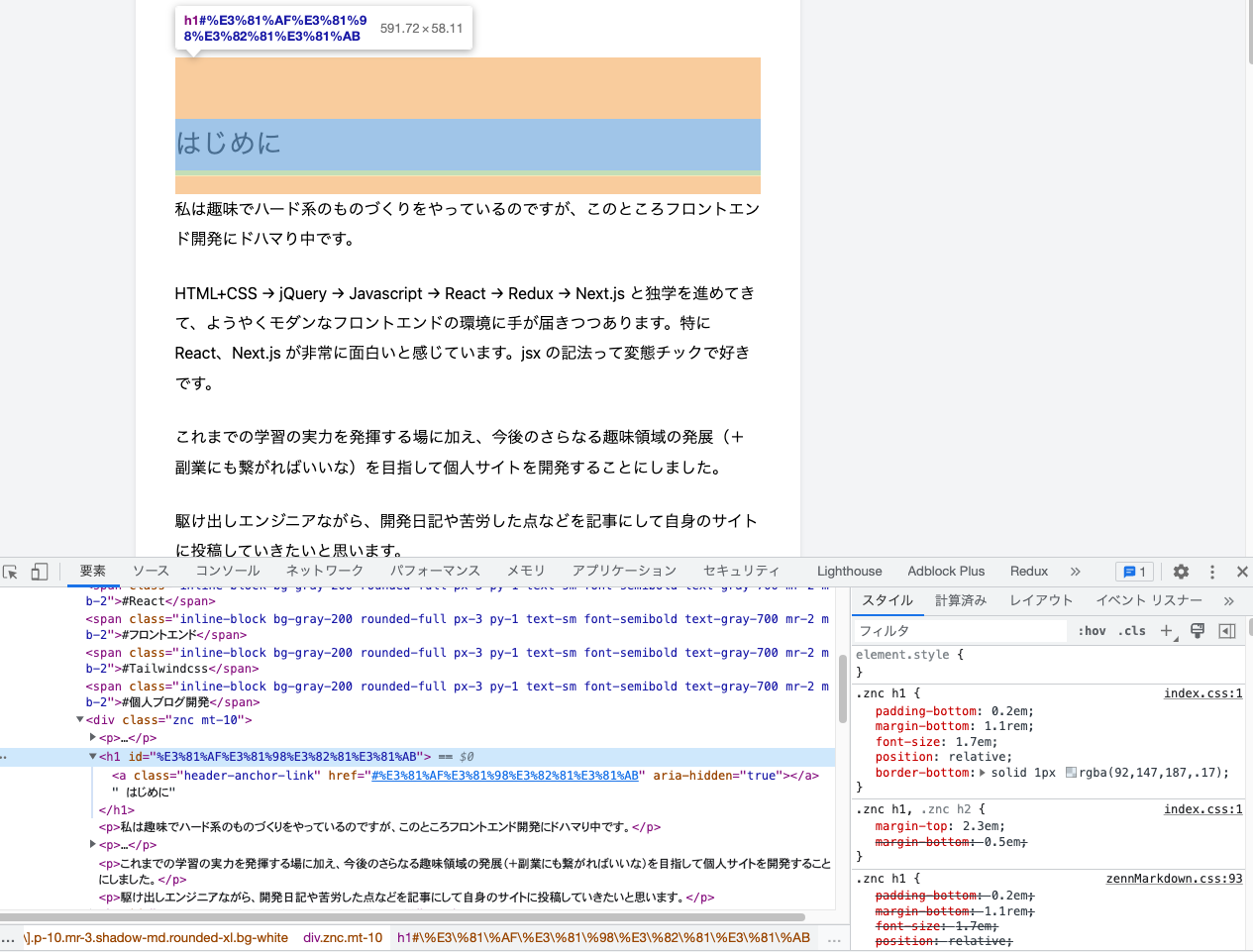
なるほど、h タグの id にタイトル名をパーセントエンコーディングした文字列が設定されていますね。これを a タグの href 属性に指定することでページ内リンクが実現できそうです。
HTML から目次生成に必要な{h タグレベル、タイトル名、href 属性}の情報を抽出するコードを getStaticProps 関数内に書きます。
type BlogData = {
id: string,
title: string,
topics: string[],
published_at: string,
thumbnail: string,
blogContentHtml: string,
};
type TableOfContent = {
level: string,
title: string,
href: string,
};
/**
* 静的ページ生成に必要なデータを生成し、コンポーネントにpropsとして渡す
*/
export const getStaticProps: GetStaticProps = async (context: any) => {
// ブログ記事markdownをHTML(string)に変換する
const blogData: BlogData = await getBlogContentData(context.params.id);
// HTML(string)をHTML(DOM)に変換する
const domHtml = new JSDOM(blogData.blogContentHtml).window.document;
// DOMから目次を検索し、{hタグレベル、タイトル名、リンク先}、を取得する
const elements = domHtml.querySelectorAll<HTMLElement>("h1, h2");
const tableOfContent: TableOfContent[] = [];
elements.forEach((element) => {
const level = element.tagName;
const title = element.innerHTML.split("</a> ")[1];
const href = element.id;
const record = { level: level, title: title, href: href };
tableOfContent.push(record);
});
return {
props: { blogData: blogData, tableOfContent: tableOfContent },
};
};
type Props = {
blogData: BlogData;
tableOfContent: TableOfContent[];
};
const Blog: NextPage<Props> = ({ blogData, tableOfContent }) => {
return (
blogDataのHTMLを展開してブログ記事を表示する;
tableOfContentのHTMLを展開して目次を表示する;
)
};
これでブログ記事本文および目次情報を Props として関数コンポーネントへ渡すことができました。
完成物
関数コンポーネントで受け取った Props を展開して 、DOM 要素を生成し Tailwindcss でスタイリングを当てれば完成です。
完成形はこのようになりました。

- 目次には a タグでページ内リンクを埋め込んでおり、クリックすると該当のタグまでスクロールします。
- h1 タグと h2 タグで目次の点のスタイルを変えています
- 目次クリック時のなめらかスクロールは、css の
scroll-behavior要素で実現しています。 - ページをスクロールしても目次が追従してくる動きは、css の
sticky要素で実現しています。
一応コードも貼っておきます。
import styles from "./[id].module.css";
import Head from "next/head";
import Header from "components/Header";
import { GetStaticProps, GetStaticPaths, NextPage } from "next";
import { getAllBlogsId, getBlogContentData } from "lib/blogRead";
import "zenn-content-css";
import { JSDOM } from "jsdom";
/**
* 生成する全てのブログ記事の静的ページのパスを生成し、getStaticPropsに渡す
*/
export const getStaticPaths: GetStaticPaths = async () => {
// 全てのブログ記事(markdown)のファイル名を取得する
const paths = getAllBlogsId();
return {
paths,
// fallback = falseの場合、pathに含まれないURLにアクセスした際に404ページを表示する
// fallback = trueの場合、pathに含まれないURLに基づいた動的なページを生成できる
fallback: false,
};
};
// ----------------------------------------------------------
// ----------------------------------------------------------
type BlogData = {
id: string;
title: string;
topics: string[];
published_at: string;
thumbnail: string;
blogContentHtml: string;
};
type TableOfContent = {
level: string;
title: string;
href: string;
};
/**
* 静的ページ生成に必要なデータを生成し、コンポーネントにpropsとして渡す
*/
export const getStaticProps: GetStaticProps = async (context: any) => {
// ブログ記事markdownをHTML(string)に変換する
const blogData: BlogData = await getBlogContentData(context.params.id);
// HTML(string)をHTML(DOM)に変換する
const domHtml = new JSDOM(blogData.blogContentHtml).window.document;
// DOMから目次を検索し、{hタグレベル、タイトル名、リンク先}、を取得する
const elements = domHtml.querySelectorAll<HTMLElement>("h1, h2");
const tableOfContent: TableOfContent[] = [];
elements.forEach((element) => {
const level = element.tagName;
const title = element.innerHTML.split("</a> ")[1];
const href = "#" + element.id;
const record = { level: level, title: title, href: href };
tableOfContent.push(record);
console.log(record);
});
return {
props: { blogData: blogData, tableOfContent: tableOfContent },
};
};
// ----------------------------------------------------------
// ----------------------------------------------------------
type Props = {
blogData: BlogData;
tableOfContent: TableOfContent[];
};
/**
* 1ブログ記事のコンポーネント
*/
const Blog: NextPage<Props> = ({ blogData, tableOfContent }) => {
return (
<>
<Head>
<title>asTriggerのブログ</title>
<meta name="description" content="blog" />
<link rel="icon" href="/favicon.ico" />
</Head>
<Header pageKind="blog" />
<div className="max-w-screen-lg mx-auto px-6 py-6" id="article">
<div className="flex flex-row">
<div className="w-auto md:w-[calc(100%_-_18rem)] p-10 mr-3 shadow-md rounded-xl bg-white">
<small className="text-gray-500">投稿日 : {blogData.published_at}</small>
<h1 className="text-3xl font-bold my-3">{blogData.title}</h1>
{blogData.topics.map((topics) => {
return (
<span
className="inline-block bg-gray-200 rounded-full px-3 py-1 text-sm font-semibold text-gray-700 mr-2 mb-2"
key={topics}
>
{`#${topics}`}
</span>
);
})}
<div
className="znc mt-10"
dangerouslySetInnerHTML={{ __html: blogData.blogContentHtml }}
/>
</div>
<div className="hidden md:block w-72 ml-3">
<div className="flex flex-col sticky top-6">
<div className="p-4 shadow-md rounded-xl mb-6 bg-white ">
<p className="text-xl text-bold mb-4">目次</p>
<ul className={`${styles.ul_h1} ${styles.ul_h2}`}>
{tableOfContent.map((anchor: TableOfContent) => {
if (anchor.level === "H1") {
return (
<li className={styles.li_h1} key={anchor.href}>
<a href={anchor.href}>{anchor.title}</a>
</li>
);
} else {
return (
<li className={styles.li_h2} key={anchor.href}>
<a href={anchor.href}>{anchor.title}</a>
</li>
);
}
})}
</ul>
</div>
</div>
</div>
</div>
</div>
</>
);
};
export default Blog;
参考文献
Trying to use the DOMParser with node js
HTML 要素の一覧および型
コメント
※ このサイトはreCAPTCHAによって保護されています。Google社のプライバシーポリシーと利用規約が適用されます。
※ 管理者が社会通念上不適切と判断した投稿は、事前通知なしに削除させていただきます。
